
この記事でわかること
・LLMの精度を向上させるためのデータの重要性
・データ作成における「エキスパート」の重要性
・作って終わりではない、データ作成プロジェクトチーム間のコミュニケーションの大切さ
よろしくお願いいたします。まず初めに簡単に自己紹介をお願いしてもよろしいでしょうか。
>関根さん
僕は35年間自然言語の研究を続けていまして、現在もこの理化学研究所 革新知能統合研究センター(以下、理研AIP)で日本語のLLM開発に携わっています。遡ると、東工大を卒業後、松下電器(現パナソニック)に入社しました。そこで色々と研究をした後、ニューヨーク大学で博士号を取得し、准教授を務めていました。その間にランゲージクラフトという会社を設立したり、楽天のニューヨーク研究所の所長を務めたりしました。8年前からは理研AIPでチームリーダーとして構造化知識の構築を行い、2023年から日本語LLMのデータ開発を始めました。現在は情報学研究所の大規模言語モデル研究開発センターの特任教授も兼任して、LLMの研究開発を進めています。
ありがとうございます。今携わっているプロジェクトの詳細を伺えますか?
>関根さん
皆さんもご存じの通り、2022年11月に『ChatGPT』が一般公開されましたよね。このChatGPTは私が研究していたタスクに対してもとても精度が高かったんです。その結果を見て「もう私のやることはないのかな…」と、自然言語研究そのものを諦めようかと思っていたんです。しかしその後、2023年の夏頃ですかね、当時一緒にいた仲間と話し合って「やっぱり日本語でLLMを作らなきゃ」と思うようになりました。
LLM開発に着手された背景にはそんなヒストリーがあったんですね。
>関根さん
はい。ChatGPTが2022年3月に出した論文の中に、インストラクションデータが非常に大事だったということが書かれていたんです。私がその当時やっていた研究で、私の身の回りにとても優秀なアノテーターさんたちがいて、「このインストラクションデータはこのチームで作れるんじゃないか?」と感じまして…。データを作成して、どうにか日本語オリジナルのLLM開発、精度向上にチャレンジしてみようと思い始めたのが、昨年8月頃でした。ただ、当時お金がなくて…。
どのように工面されたんですか。
>関根さん
試しにいくつか作ってみて、ChatGPTの論文並みに、1万件作るには2000万円かかると推測しました。そこで、200万円で10社くらいの企業と共同研究を行えれば良いな、と考えました。しかし、実際には21社からの申し込みがあり、皆さんと共同研究を行いながら1万件のデータ作成を始めました(注:実際は18社との共同研究が成立)。最初は15名のアノテーターでインストラクションデータの作成を行っていましたが、次第にこの人数では作成しきれないことがわかり、APTOさんを含むアノテーション企業の3社に発注し始めました。
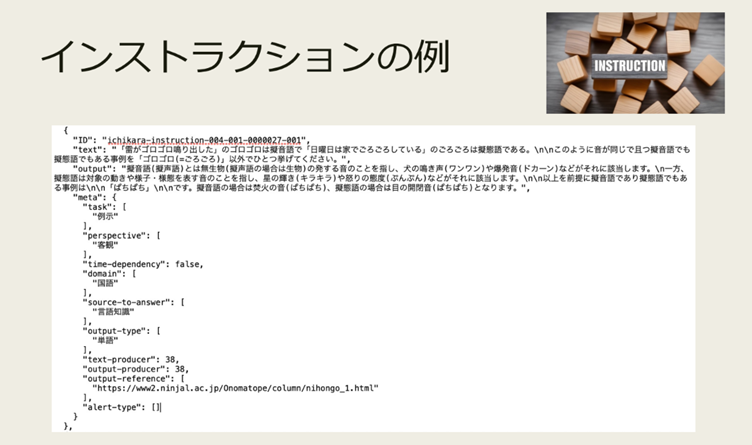
日本語のLLMを構築する上で、どのような課題がありましたか?
>関根さん
第一に、限られた予算とリソースで、効率的に高品質なデータを作る必要がありました。インストラクションデータの作成は、実際にやってみると非常に手間のかかる作業で、国語が得意な人たちの中でも特性があり、実際には誰でもできる作業ではないんです。まずは、訓練されたアノテーターが「質問」と「答え」をセットで作成し、制作物の品質管理を別のメンバーが丁寧に行う、そういったプロセスを踏まないと、高品質な日本語のLLMはなかなかできないことがわかりました。
もう少し作業について詳しく教えていただけますか?
>関根さん
まず、様々なカテゴリごとに質問を作成していきます。質問は様々なタイプがあり、例えば要約(=まとめてください)や例示、抽出(=抜き出してください)、翻訳…etc. といった具合ですね。答えであれば文章、固有名詞、プログラム、などこちらもジャンルが多数ありまして、それぞれのカテゴリのデータが一定数必要なので、これが大変なのです。
確かに、聞いているだけで膨大な時間がかかりそうだな…と思いました。
>関根さん
これらをAPTOさんにも作っていただいて、一部の精度の低いものを除き、ほとんど学習させました。
人材を集めるのにも、苦労されたのではないでしょうか。
>後藤さん
そうですね。APTOさんを含む外注さんには、①プロジェクトの背景と②具体的なニーズを説明し、③スピーディに制作する必要性と、④精度の面でも高品質なデータ提供をお願いしました。初期段階では仕様書もない状態でのスタートでしたが、APTOさんをはじめとする皆さんの協力で多くのデータを効率的に作成することができました。

実際に作成したインストラクションデータの品質はいかがでしたか?
>後藤さん
当然ですが、最初は仕様書もない中で始めたこともあり、精度は決して高くありませんでした。しかしながら、丁寧で円滑なコミュニケーションが功を奏したのと、APTOさんに品質管理体制、フィードバック体制が整っていたので、精度向上のスピードが非常に速く、短期間でデータを揃えることができました。
>関根さん
結果的に、APTOさんを含む様々な方にお手伝いいただき、短期間で1万件の高品質なインストラクションデータを作成できたことが何より大きな成果です。これにより日本語LLMの精度が向上し、より正確なモデルを構築することができました。
お役に立てて、光栄です。では最後に、今後のビジョンについて教えてください。
>関根さん
今後もAPTOさんとの協力を続けながら、さらに質の高いデータを作成し、日本語のLLMの精度を向上させていきたいと考えています。また、他のプロジェクトにもAPTOさんの協力をお願いし、さらなる技術革新を目指していきたいです。
特に、日本語に特化したLLMの構築は、日本の文化や法律、社会の文脈を深く理解するために重要です。LLM開発を進めていく中で、「私たちはなぜLLMが必要なのか」「なんのために必要なのか」「どういう世界を目指しているのか」そういったことも同時に考えていく必要があるようにと今感じています。
具体的には、まだまだデータが足りていないので、より広い質問タイプでの構築も図っていきますし、自然な質問例を収集したり、マルチターンデータ・マルチモーダルデータを集めていきます。
ありがとうございました。今後もお力添えできるように、「harBest」もアップデートを重ねて参ります。今後とも、よろしくお願いいたします!
