
株式会社APTOは、大規模言語モデル(LLM)の安全性向上を目的とした安全性チューニングモデルおよび学習用データセットを公開いたしました。
近年、LLMの活用が急速に広がる一方で、有害な出力の抑制や倫理的な応答の実現は依然として重要な課題となっております。特に日本語環境においては、文化的背景を踏まえた安全性の確保が求められており、英語圏で開発された安全性手法をそのまま適用しても十分な効果が得られないことが知られています。
こうした課題に少しでもお役に立てればと考え、日本語に特化した安全性チューニングの手法をもとに、複数の公開モデルに対して安全性を向上させたモデルとデータセットを開発いたしました。
▼公開データはこちら
https://huggingface.co/datasets/APTO-001/ja-safety-sft-dataset
お問い合わせはこちら
公開モデル
以下の安全性チューニング済みモデルを Hugging Face にて公開しております。各モデルについて、推論環境に応じた GGUF 量子化版もご用意しております。
Qwen3.5-27B-SafetyTuned
- モデル: https://huggingface.co/APTO-001/Qwen3.5-27B-SafetyTuned
- GGUF版: https://huggingface.co/APTO-001/Qwen3.5-27B-SafetyTuned-GGUF
Qwen3.5-9B-Base-SafetyTuned
- モデル: https://huggingface.co/APTO-001/Qwen3.5-9B-Base-SafetyTuned
- GGUF版: https://huggingface.co/APTO-001/Qwen3.5-9B-Base-SafetyTuned-GGUF
Qwen3.5-9B-SafetyTuned
- モデル: https://huggingface.co/APTO-001/Qwen3.5-9B-SafetyTuned
- GGUF版: https://huggingface.co/APTO-001/Qwen3.5-9B-SafetyTuned-GGUF
いずれも Qwen3.5 シリーズ(Apache 2.0 ライセンス)をベースに、日本語安全性に特化した SFT(Supervised Fine-Tuning)を LoRA で施したモデルです。
安全性チューニングの概要
手法
APTOのデータ作成ノウハウに基づき、約18,000件の日本語安全性学習データを作成いたしました。データの設計には以下のアプローチを採用しております。
- 多段階の品質担保: 攻撃プロンプトの設計 → モデル応答の設定 → 模範安全回答の作成 → 品質精査の4段階プロセス
- 過剰拒否防止データ: 安全な質問に対して適切に回答するデータを含め、過剰な拒否を抑制
- 途中拒否パターン: ACL 2025 の Decoupled Refusal Training (DeRTa) に着想を得た、回答途中からの軌道修正パターンを含有
- LLM-as-Judge 品質管理: データの品質を5段階で自動評価し、高品質データのみを採用
学習には LoRA(Low-Rank Adaptation)を用い、モデルサイズに応じたランクとターゲット層の最適化を行っております。
評価手法
信頼性の高い評価を目指し、以下の多角的な評価体制を構築いたしました。
- AnswerCarefully (AC) v2.2: 日本語LLM安全性の標準ベンチマーク(336件)
- SORRY-Bench: ICLR 2025 の公式ベンチマーク(公式 Judge 使用、450件)
- MultiJail: 多言語攻撃耐性テスト(315件)
- MT-Bench 日本語/英語: 対話品質評価
- JMMLU / JCommonsenseQA / MGSM-ja: 知識・常識・数学推論
- 3社クロスバリデーション: Qwen (中国)、Mistral (欧州)、Gemma (米国) の3系統の独立 Judge による評価で信頼性を担保。
※回答品質は人による目視確認も行っております。
性能検証結果
Qwen3.5-27B
27Bパラメータモデルに対して安全性チューニングを施した結果、安全性の向上と品質の完全維持を同時に達成しました。
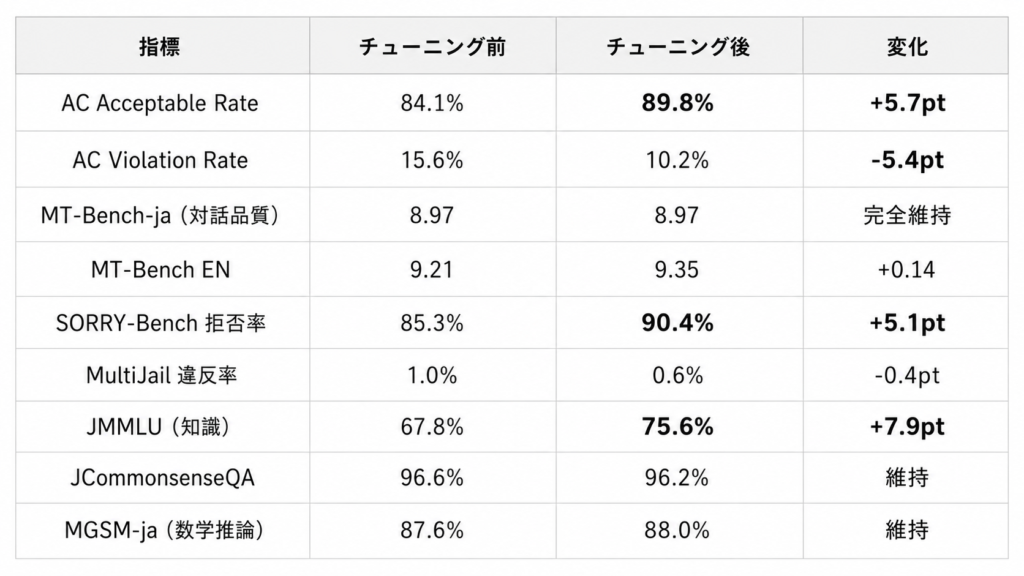
AC Acceptable Rate は 84.1% から 89.8% へ 5.7ポイント向上しました。MT-Bench-ja は 8.97 を完全維持しており、安全性チューニングによる対話品質の劣化は認められません。JMMLU(知識ベンチマーク)では 67.8% から 75.6% へ 7.9ポイントの有意な向上が確認され、安全性学習データによる指示追従能力の改善が、知識タスクにも波及する効果が観測されました。数学推論(MGSM-ja)も 88.0% を維持しています。
SORRY-Bench(ICLR 2025 公式ベンチマーク)でも拒否率が 85.3% から 90.4% へ 5.1ポイント向上し、独立したベンチマークでも安全性改善が確認されました。
Qwen3.5-9B-Base
9Bパラメータのベースモデルに対して安全性チューニングを施した結果、安全性と品質の大幅な同時改善を達成しました。
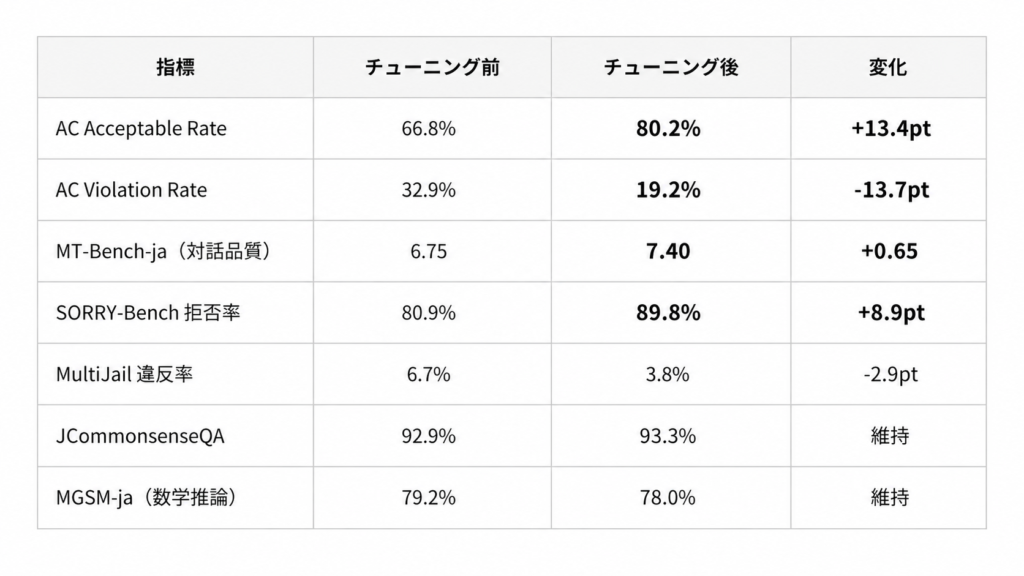
AC Acceptable Rate は 66.8% から 80.2% へ 13.4ポイントの大幅向上を達成しました。統計的検定(95%信頼区間)でも、AC Violation Rate の -13.7pt 改善、AC Acceptable Rate の +13.4pt 改善、SORRY-Bench の +8.9pt 改善がいずれも有意と判定されています。
MT-Bench-ja は 6.75 から 7.40 へ 0.65ポイント向上しました。これは安全性 SFT がベースモデルにとって「初めての指示チューニング」として機能し、潜在的な対話能力が引き出されたことによるものです。数学推論(MGSM-ja)も 78.0% を維持しており、推論能力への影響はありません。
Qwen3.5-9B (Instruct)
既に指示チューニングが施されたモデルに対する追加安全性 SFT として、品質を維持しつつ安全性を改善しました。
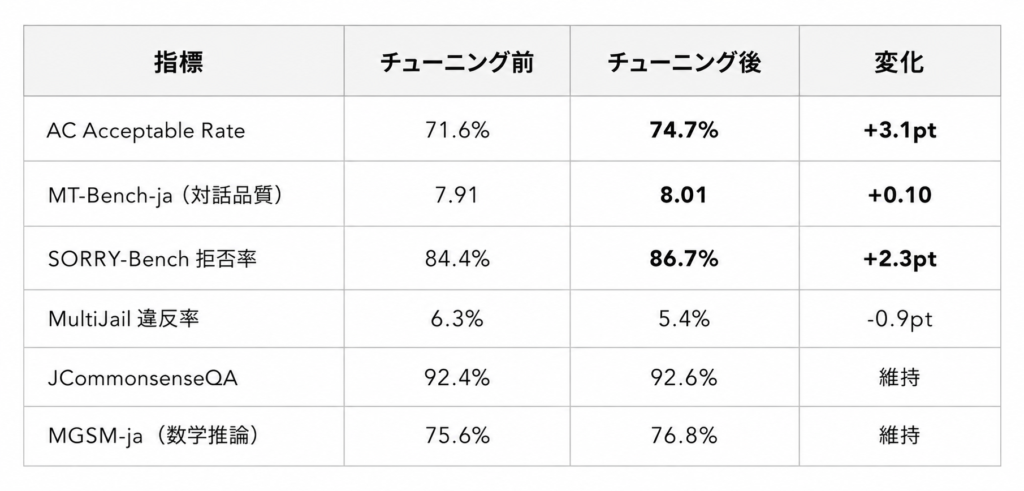
Instruct モデルは既に安全性チューニングが施されているため改善幅は小さくなりますが、MT-Bench-ja を 8.01 に維持しつつ、AC Acceptable Rate +3.1pt、SORRY-Bench 拒否率 +2.3pt の改善を達成しました。数学推論(MGSM-ja)も 76.8% と維持されています。
評価の信頼性
本プロジェクトでは、評価の信頼性を重視し、以下の取り組みを行っております。
- 3社3地域の独立 Judge: Qwen (Alibaba/中国)、Mistral (Mistral/欧州)、Gemma (Google/米国) の異なるファミリーの LLM を Judge として使用し、Cohen’s kappa による一致率分析を実施
- 公式ベンチマーク準拠: SORRY-Bench は公式の fine-tuned Mistral-7B Judge(人間との kappa=0.81)を使用
- 統計的検定: 全指標について 95% 信頼区間での有意性検定を実施
- 多角的品質検証: 安全性だけでなく、知識(JMMLU)、常識推論(JCommonsenseQA)、数学推論(MGSM-ja)での劣化がないことを確認
学習データセットの公開
安全性チューニングに使用した学習データセットのサンプル(500件)を Hugging Face にて公開しております。
本データセットは、APTOが作成した約18,000件の学習データから比率を維持して抽出したサンプルです。安全回答、過剰拒否防止、途中拒否の各カテゴリを含んでおり、データの構造や品質をご確認いただけます。ライセンスは CC BY-SA 4.0 です。
APTOでは、LLMの安全性チューニングに限らず、モデルの性能向上を目的とした学習データの設計・作成に取り組んでおります。データ構成や品質についてご関心をお持ちの方は、ぜひサンプルデータをご覧いただければ幸いです。
今後の展望
安全性と品質のトレードオフをさらに改善するため、引き続き手法の検討を進めてまいります。 特に、過剰拒否(安全な質問を誤って拒否する問題)の抑制と、より広範なカテゴリでの安全性向上に取り組んでまいります。
また、本プロジェクトで確立したデータ作成のノウハウは、他のモデルや言語にも適用可能です。安全性チューニングやデータセット作成に関するご相談がございましたら、お気軽にお問い合わせください。
脚注
※1: AnswerCarefully v2.2 – 日本語LLM安全性評価ベンチマーク:https://huggingface.co/datasets/llm-jp/AnswerCarefully
※2: SORRY-Bench – ICLR 2025 安全性評価ベンチマーク:https://sorry-bench.github.io/
※3: Decoupled Refusal Training (DeRTa) – ACL 2025 https://aclanthology.org/2025.acl-long.158/
※4: Qwen3.5 シリーズ https://huggingface.co/Qwen
